Week 3 at AI_devs: Mastering Data Organization and Retrieval

Table of Contents
Welcome to my summary of Week 3 at AI_devs. After exploring multimodal models in Week 2, this time we focused on data - specifically how to effectively prepare, organize, and retrieve information for LLM consumption. We covered practical aspects of working with various data sources, from vector databases to graph databases. Let’s dive in.
AI_devs summaries:
- Week 1 at AI_devs: From LLMs to Intelligent Agents
- Week 2 at AI_devs: Exploring Multimodal AI
- Week 3 at AI_devs: Mastering Data Organization and Retrieval (current post)
- Week 4 at AI_devs: Building AI Agent Tools and Interfaces
- Week 5 at AI_devs: Building Advanced AI Agents and course summary
Introduction
This week we dove deep into advanced data processing and retrieval techniques - crucial skills for building sophisticated AI agents. Our lessons covered five main areas:
- Document processing and
chunking strategies Semantic searchusing vector databasesHybrid searchimplementations- File format processing
- Graph databases for
knowledge organization
Here’s what I learned throughout the week.
Day 1: Document Processing and Data Organization
The first day refreshed and deepened our understanding of document processing for LLMs. While we touched on this topic in previous weeks, now we explored more advanced concepts and strategies. The course introduces the concept of documents - a unified structure for all data types that combines main content with descriptive metadata and context information.
One of the key challenges we addressed is working within LLM context window limitations. This often requires splitting source materials into multiple smaller documents. The process looks like this:
- Splitting content into appropriate chunks (using various strategies)
- Enriching each chunk with relevant metadata
- Creating relationships between documents
The metadata structure varies by use case but typically includes source information, context details, and filtering parameters - all crucial for effective retrieval later.
This approach forms the foundation for RAG (Retrieval-Augmented Generation) systems. We compared two RAG implementations: the standard approach and Anthropic’s Contextual Retrieval Preprocessing method. The latter, detailed in Anthropics excellent blog post, offers significant improvements in context handling during document retrieval - I highly recommend reading it if you’re interested in advanced RAG implementations.
Practical Task: Contextual Keyword Enhancement
The day’s task focused on document preparation and relationship building. We received several text documents and needed to process them appropriately, including generating keywords. The interesting challenge was creating cross-document relationships - for instance, if one document mentioned a person and another contained detailed information about them, we needed to enrich the first document’s keywords with relevant details from the second.
I implemented the solution in Go, utilizing two new (for me) libraries:
github.com/Azure/azure-sdk-for-go/sdk/ai/azopenai- Microsoft’s SDK which works seamlessly with OpenAI’s APIgithub.com/tiktoken-go/tokenizer- for monitoring token usage in generated documents
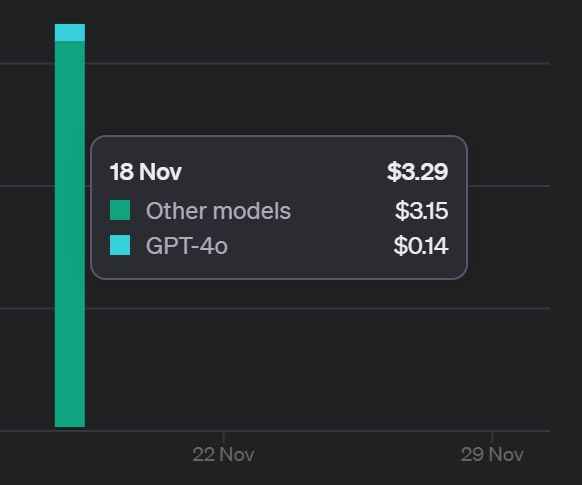
A Costly Typo: The Importance of Model Selection
While configuring the project, I made a simple typo in the model name - used gpt-4 instead of gpt-4o. This single-character mistake led to a significant cost difference when running the same set of tasks:
- GPT-4: $3.15
- GPT-4o: $0.14
Yes, you’re seeing it right - that’s over a 23x difference in cost! A simple typo resulted in an extra $3 expense. This experience taught me two crucial lessons:
- Always double-check model configurations before running tasks
- Set up proper monitoring to catch such issues early
This kind of mistake might seem minor in development, but could become very expensive when running in production. It’s a perfect example of why monitoring tools like LangFuse aren’t just nice-to-have but essential for AI development.
Day 2: Semantic Search Implementation
Building on Day 1’s document processing foundations, we explored how to effectively retrieve documents using semantic search with vector databases. We primarily worked with Qdrant.
The quality of LLM responses heavily depends on how effectively we can retrieve relevant information. This is where embeddings come into play - numerical representations of data that capture semantic meaning. These embeddings, along with metadata, are stored as “points” or “documents” in a vector database, essentially creating a semantic search engine.
The process involves two main operations:
- Storing data: Generate embeddings for documents and store them with metadata
- Querying: Create embeddings for queries and find similar documents
Here’s a simplified example of storing documents in a vector database:
// generate unique doc identifier
docId, err := tools.GenerateFileID(path)
// read file
content, err := os.ReadFile(path)
// create document
doc := textservice.Document(string(content))
// create embedding
embeddings := customopenaiwrapper.GetEmbeddings(doc.Text)
// add document to the database
wrapper.AddPoint(doc, embeddings, docId)
And querying them:
// your question
question := "in the report from which day is there a mention of ... ?"
// create embedding for you question
questionEmbeddings := GetEmbeddings(question)
// you can limit the response
limit := uint64(1)
// query to database using embeddings
result, err := wrapper.QueryWithLimit(questionEmbeddings, &limit)
For this implementation, I used a document structure that included both content and relevant metadata:
doc := &Doc{
Text: text,
Metadata: Metadata{
Tokens: tokens,
Headers: Headers{},
URLs: []string{},
Images: []string{},
},
}
Practical Task: Event Discovery in Vector Space
The day’s assignment involved processing a set of documents to locate specific event descriptions using vector search. This was particularly engaging as it provided my first hands-on experience with vector databases in a practical context.
Are you interested in staying up-to-date with the latest developments in #Azure, #CloudComputing, #PlatformEngineering, #DevOps, #AI?
Follow me on LinkedIn for regular updates and insights on these topics. I bring a unique perspective and in-depth knowledge to the table. Don't miss out on the valuable content I share – give me a follow today!
Day 3: Advanced Search Techniques
After mastering vector databases, we explored how combining different search strategies can lead to better results. Vector databases alone, while powerful, aren’t always sufficient for every search scenario. This is where hybrid search comes into play.
The concept is straightforward: combine results from multiple data sources to enhance search effectiveness. For example, when searching for a book by ISBN, a traditional SQL database might provide more accurate results than semantic search. This hybrid approach allows us to leverage the strengths of different search methods:
- Vector databases for semantic understanding
- SQL databases for exact matches
- Full-text search for keyword matching
The implementation follows the following process:
- Query multiple data sources concurrently
- Combine results into a single list
- Calculate scores, for example by using a formula like
(1 / vector_rank) + (1 / full_text_rank) - Sort by final score
- Return top results
We also explored an interesting concept called self-querying. Consider an AI agent receiving a casual greeting like Hey there! What's up?. Neither semantic nor traditional search would be particularly helpful here. However, by considering contextual factors like time of day, location, or the agent’s basic information, the model can generate multiple self-directed questions that lead to meaningful search queries.
Practical Task: SQL Generation with LLM
The day’s assignment focused on working with traditional SQL databases, but with a creative challenge - using LLM to generate SQL queries. Rather than writing SQL manually, we needed to craft an effective prompt that would make the model generate accurate SQL queries to extract specific information from the database.
Day 4: Managing Data Sources
While modern LLMs offer impressive multimodal capabilities for processing images, audio, and video, handling various file formats still presents significant challenges. Our applications need various mechanisms for format conversion (like xlsx to csv or docx to HTML) to make content accessible to language models. Day four focused on these practical strategies for processing different data formats and integrating them into our AI applications.
Text files are the simplest to handle - their straightforward structure allows direct processing with minimal transformation.
Office documents like DOCX and XLSX follow a more complex path -we can use services like Google Docs to convert them to HTML or CSV formats.
PDF documents present the biggest challenge and aren’t well-suited for complex structures. However, they work well enough for structured content like invoices, where we combine screenshot capture with text extraction where possible.
Audio processing involves several steps: initial silence detection for segmentation, smart chunking with buffer zones, conversion to optimized OGG format, and finally transcription using OpenAI Whisper.
Images are processed through Vision Language Models (VLM) to generate text descriptions - a limited but useful approach.
Web content, on the other hand, can be effectively processed using tools like FireCrawl, which handles HTML content extraction and cleaning, converting everything to markdown for consistency.
Practical Task: Multi-Query SQL Optimization
The day’s challenge involved working with SQL databases again, but this time focusing on optimization scenarios requiring multiple sequential queries.
Day 5: Graph Databases
Our final day introduced graph databases, specifically Neo4J, as a powerful tool for organizing and querying connected data. Sometimes keyword matching or semantic search isn’t enough, even with filters. That’s where graph databases shine - they excel at finding relationships between data points.
While full-text and semantic search work well for finding specific information in datasets, they struggle with seeing the bigger picture or finding connections between pieces of information. Graph databases solve this by allowing us to build and navigate relationships between documents. Think of it as a web of connected information rather than a flat list of documents.
Getting data into a graph database can happen in two ways:
- Structuring existing data (like web content)
- Building relationships from scratch through AI agent interactions
Tools like GraphRAG can help convert unstructured text into connected documents. This structured data then serves as context for RAG systems, making them more effective at understanding relationships between different pieces of information.
One interesting aspect is how we can use LLMs to help build these connections, though we can also use specialized domain models for specific use cases. The key is understanding when to use graph databases - they’re particularly useful when relationships between data are as important as the data itself.
Practical Task: Social Network Graph Navigation
The day’s hands-on task gave us practical experience with Neo4J. We received two JSON datasets - one containing a list of people and another describing connections between them (who knows whom). The challenge had two main parts:
- Build a graph structure showing relationships between people
- Query the shortest path between Person A and Person B
Wrapping Up
Week 3 of AI_devs focused on advanced data preparation and retrieval techniques for AI applications. We explored document processing strategies, semantic and hybrid search implementations, and the potential of graph databases for organizing connected data.
This week highlighted the importance of structuring information for LLMs, with practical insights into chunking, metadata enrichment, and embedding creation. Tools like Qdrant and Neo4J showed how diverse approaches to data storage and retrieval can address different challenges.
Thanks for reading! See you next week for more insights and hands-on experiences.
Do you like this post? Share it with your friends!
You can also subscribe to my RSS channel for future posts.