Week 2 at AI_devs: Exploring Multimodal AI

Table of Contents
Welcome back to my journey through the AI_devs course! After diving into the fundamentals of LLM interaction in Week 1, this second week took us into the exciting realm of multimodal AI - where language models meet audio, vision, and image generation capabilities.
AI_devs summaries:
- Week 1 at AI_devs: From LLMs to Intelligent Agents
- Week 2 at AI_devs: Exploring Multimodal AI (current post)
- Week 3 at AI_devs: Mastering Data Organization and Retrieval
- Week 4 at AI_devs: Building AI Agent Tools and Interfaces
- Week 5 at AI_devs: Building Advanced AI Agents and course summary
Introduction
This week we explored systems that integrate multiple AI modalities - text, speech, vision, and image generation. Moving beyond text-based interactions, we learned to build applications that can process speech, analyze images, generate graphics, and combine these different modes of interaction.
Throughout the week, we covered several key areas:
- Building voice interfaces using
Text-to-SpeechandSpeech-to-Textmodels - Working with
Vision Language Modelsfor image understanding and analysis - Implementing AI image generation and manipulation systems
- Creating applications that combine multiple AI models for enhanced capabilities
- Developing practical tools that leverage multimodal AI in real-world scenarios
These technologies are becoming more accessible to developers. While major AI companies demonstrate sophisticated multimodal capabilities in controlled environments, we focused on building practical applications that leverage these technologies within their current limitations.
Let me share what I learned during this week of working with multimodal AI.
Day 1: Building Voice Interfaces
Building modern voice interfaces requires understanding three core components of audio processing. At the input stage, we handle audio sources like microphones or audio files. The processing logic layer manages transcription and response generation. Finally, the output stage delivers either streamed audio or audio files back to the user.
This process relies on three distinct types of AI models working together:
Speech-to-Textmodels like Whisper, Deepgram, or AssemblyAI convert audio to text, with some even supporting speaker recognitionLarge Language Modelsfrom providers like OpenAI and Anthropic handle understanding and response generationText-to-Speechmodels such as OpenAI TTS and ElevenLabs convert the responses back to audio
Building effective voice interfaces requires addressing several technical challenges. Audio format selection is crucial - WAV provides better quality but OGG offers size optimization. Silence detection plays a vital role, as models like Whisper may generate text even for silent audio segments.
The lesson demonstrated that while these individual components work well independently, creating a complete voice interface requires careful integration and error handling. Current limitations include occasional confabulation, limited control over output style, and token window constraints - challenges shared with traditional language models.
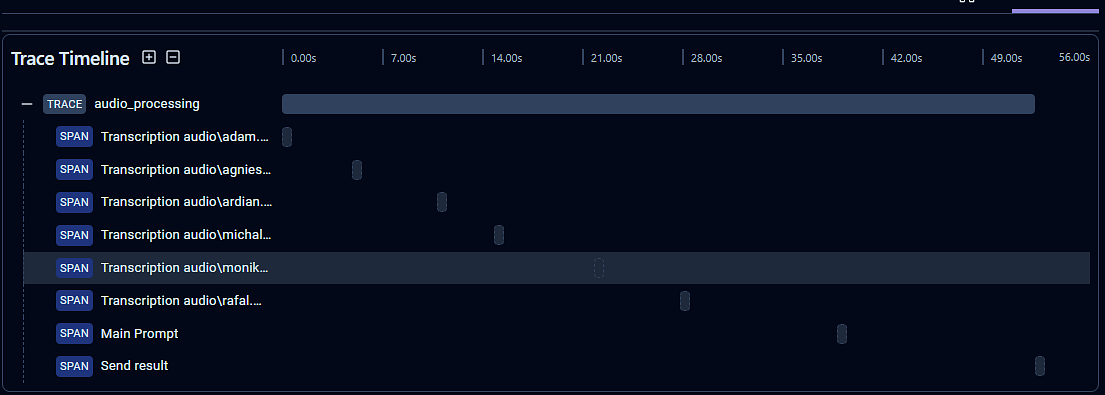
Practical Task: Audio Investigation Analysis
The task involved processing several MP3 files containing recordings from fictional interrogations. The challenge went beyond simple transcription - we needed to:
- Generate accurate transcripts using the
whisper-1model - Build appropriate context for understanding the conversations
- Extract insights that weren’t explicitly stated in the recordings
I developed a solution in GoLang that handled the entire processing flow.
This task also marked my first integration with LangFuse, which provided valuable monitoring capabilities and improved the observability of the entire process.
Day 2: Vision Language Models in Practice
Multimodal models like GPT-4o and Claude 3 Sonnet have expanded beyond text processing to include image analysis capabilities. These Vision Language Models (VLMs) can process images while leveraging their text understanding abilities, opening new possibilities for automated visual analysis.
The interaction with VLMs follows the familiar ChatML format, but with a key difference: the content property accepts an array that can include both image_url and text objects.
openai.ChatCompletionRequest{
Model: openai.GPT4oMini,
Messages: []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleUser,
MultiContent: []openai.ChatMessagePart{
{
Type: openai.ChatMessagePartTypeText,
Text: "Describe in detail what you see in this image.",
},
{
Type: openai.ChatMessagePartTypeImageURL,
ImageURL: &openai.ChatMessageImageURL{
URL: fmt.Sprintf("data:image/jpeg;base64,%s", base64Img),
},
},
},
},
},
},
This allows sending multiple images within a single conversation. However, due to the stateless nature of LLM APIs, images are reinterpreted with each request, which can impact costs significantly.
VLMs share common limitations with text-based models, such as hallucinations and context window constraints, while introducing new challenges specific to image processing. Yet they also benefit from similar prompt engineering techniques, including Self-Consistency and Chain of Thought approaches.
Current capabilities and limitations of VLMs present an interesting mix:
- They excel at OCR tasks, though occasional errors still occur
- They can identify colors but cannot return specific values like HEX codes
- They struggle with precise measurements and spatial relationships
- They cannot determine exact image dimensions or element positions
- They’re constrained by their knowledge cutoff, limiting recognition to known concepts
- They remain vulnerable to prompt injection, which can be embedded directly in images
Implementation can be enhanced through programmatic control, utilizing file system access, system clipboard, network connectivity, or mobile device cameras. For tasks requiring precise measurements or object detection, supplementary tools like Meta's Segment Anything can be usefull. Recent models, such as Anthropic’s latest versions, show improved pixel computation capabilities, particularly in Computer Use scenarios.
Practical Task: Map Analysis Challenge
In this lesson, our task was to analyze images of certain maps and identify which Polish city they came from. I managed to solve this without AI … I know, shame on me! I haven’t mentioned this before, but besides lessons and assignments, we have various side tasks in the course, usually unrelated to the lesson topic or even training. As a small justification, I’ll add that today’s side task was extremely interesting and kept me busy for quite a while :)
Are you interested in staying up-to-date with the latest developments in #Azure, #CloudComputing, #PlatformEngineering, #DevOps, #AI?
Follow me on LinkedIn for regular updates and insights on these topics. I bring a unique perspective and in-depth knowledge to the table. Don't miss out on the valuable content I share – give me a follow today!
Day 3: Mastering AI Image Generation
The third day focused on practical applications of AI image generation. The lesson covered both cloud-based solutions like DALL-E 3 and local deployment options for image generation models (ComfyUI!!).
Building applications with image generation requires understanding both model capabilities and implementation constraints. While current models can create high-quality visuals, successful implementation relies on careful prompt engineering and structured workflow design. The lesson demonstrated the importance of structured approaches to image generation, particularly when working with specific guidelines or brand requirements.
Practical Task: Image Generation Challenge
The task involved generating specific images based on provided guidelines. I developed a solution in GoLang that interfaced with the DALL-E 3 API. The application needed to:
- Process the guideline document
- Generate appropriate prompts
- Submit results for verification
The implementation was again monitored using LangFuse.
The most challenging aspect was creating the perfect prompt. Unlike conversational prompts, image generation prompts require a different mindset - you need to be both precise and descriptive while avoiding ambiguity.
ComfyUI
During this lesson, I discovered ComfyUI, a powerful tool for working with local image generation models. It provides a node-based interface for creating custom generation workflows, offering precise control over the entire process. This approach is particularly valuable when working with specific requirements or attempting to maintain consistent output quality.
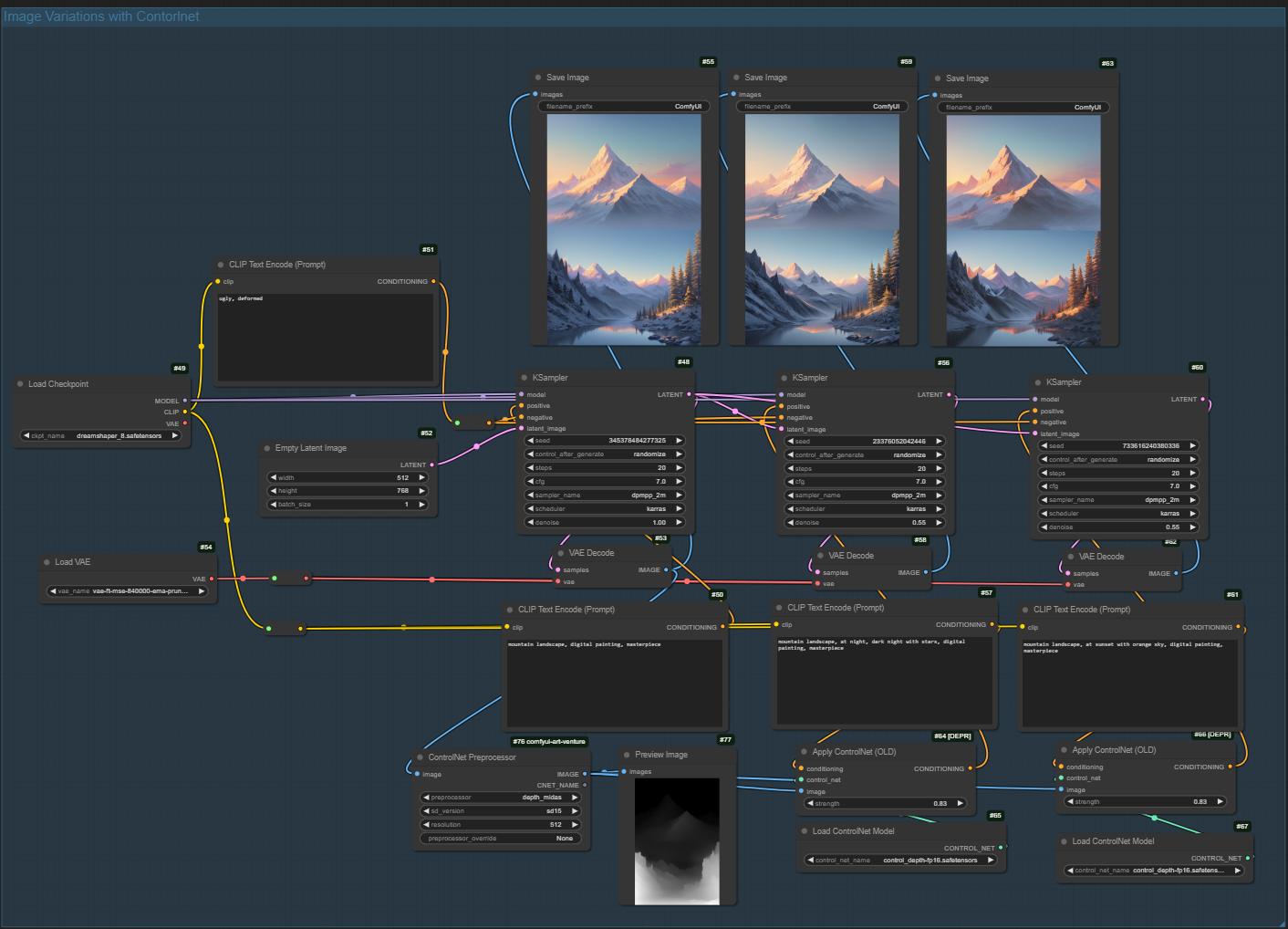
Through experimenting with ComfyUI, I progressed from using the basic Stable Diffusion 1.5 model to SDXL, and currently find the Flux 1d model particularly effective. The tool’s ability to save and modify workflows makes it an excellent choice for systematic image generation tasks.
For those interested in exploring ComfyUI, numerous tutorials are available on YouTube that demonstrate its capabilities, like:
Day 4: Multimodal Model Integration
The fourth day explored the integration of multiple AI models to process different content formats effectively. As models evolve, we’re seeing increased capabilities in handling text, audio, images, and even video content. This multimodal approach allows for more comprehensive content processing and analysis.
The lesson demonstrated how different models can work together while maintaining context across formats. For example, when processing documents, we can use vision models to analyze embedded images, transcription models for audio content, and language models to generate comprehensive summaries. This combination provides richer understanding than any single model could achieve.
A significant portion of the lesson focused on practical implementation challenges, such as managing response times, optimizing costs, and ensuring consistent quality across different content types. The lesson showed that while multimodal processing offers powerful capabilities, it requires careful consideration of system architecture and model selection.
Practical Task: Multi-Format Classification
We received a set of files in different formats (txt, mp3, and png) and needed to classify them into appropriate categories. This was a practice exercise that helped reinforce our previous work with different file formats.
I built a solution using two models:
GPT-4o-minifor text processing and classificationwhisper-1for audio transcription
This task seemed simple at first, but it taught me an important lesson about Large Language Models - they are non-deterministic. While most queries correctly categorized the materials, the models sometimes produced different results for the same input. This inconsistency showed how important it is to test prompts thoroughly. Tools like PromptFoo helped here, letting me test the same prompts multiple times to check their reliability.
Day 5: Practical Applications of Multimodal AI
The final day of Week 2 focused again on practical applications of multimodal AI, specifically looking at how different content formats can be processed and combined effectively. The lesson explored various real-world scenarios where text, audio, and images need to be analyzed together to extract meaningful information.
A significant portion of the lesson covered transforming content between formats. We learned about adapting text for audio needs, including proper formatting and style considerations. This process involves more than simple conversion - it requires understanding how content should be structured for effective audio presentation.
Practical Task: Multimodal Document Analysis
We received a large document containing text, embedded images, and MP3 recordings. Our task was to process this content and answer several specific questions. While text processing was straightforward, images and audio required additional preparation - each needed to be described in a way that made their content searchable alongside the text.
The challenge came from questions that required connecting information across different formats. For example, one question asked about a specific city that wasn’t explicitly named in the text but could be identified from an image of its market square. This required:
- Creating accurate descriptions of images
- Transcribing audio content
- Combining information from all sources
- Drawing conclusions from the combined data
This task demonstrated that effective multimodal processing requires more than just handling different formats independently. Success depends on maintaining relationships between content types and understanding how they complement each other. The ability to connect information across formats proves particularly valuable when answers aren’t explicitly stated in any single source.
Key Takeaways from Week 2:
Voice Interfaces Are Evolving
- Modern TTS and STT models offer impressive capabilities
- Building real-time voice interactions is becoming feasible
- Audio processing requires careful attention to context and quality
Vision Models Are Powerful but Limited
- VLMs can understand complex visual content
- Understanding their limitations is crucial for effective implementation
- Combining multiple models can overcome individual limitations
Image Generation Is Becoming More Accessible
- Tools like ComfyUI make local image generation practical
- Workflow-based approaches offer better control and consistency
- Prompt engineering for images requires different strategies than text
Model Integration Is Key
- Different models can complement each other’s strengths
- Managing multiple models requires careful orchestration
- Non-deterministic behavior needs to be handled appropriately
Essential Tools Discussed This Week:
- ComfyUI: A powerful tool for creating image generation workflows
- Whisper: OpenAI’s robust speech-to-text model
- LangFuse: For monitoring and debugging multimodal AI applications
- PromptFoo: Essential for testing and validating prompts across different scenarios
Wrapping Up
Week 2 of AI_devs focused on multimodal AI applications, exploring how different AI models can work together with various content formats. We covered voice interfaces, vision models, image generation, and practical ways to integrate these technologies.
The progression from text-only applications in Week 1 to multimodal systems this week showed both the potential and challenges of working with different content types. While models like Whisper and GPT-4o offer impressive capabilities, successful implementation requires understanding their limitations and appropriate use cases.
A particularly valuable discovery was ComfyUI for image generation workflows, demonstrating how specialized tools can significantly improve the development process.
Next week, we’ll explore AI Agents development, building on these multimodal foundations. See you then!
Do you like this post? Share it with your friends!
You can also subscribe to my RSS channel for future posts.