Week 1 at AI_devs: From LLMs to Intelligent Agents

Table of Contents
Large Language Models (LLMs) are becoming a new type of computing platform, and knowing how to work with them is quickly becoming as essential as understanding traditional programming. Join me on my journey through AI_devs course, where I’m learning to transform LLMs from simple chatbots into powerful, autonomous agents that can actually get things done.
In this weekly series, I’ll share my journey of learning how to build these intelligent systems, starting with the foundations I learned in Week 1.
AI_devs summaries:
- Week 1 at AI_devs: From LLMs to Intelligent Agents (current post)
- Week 2 at AI_devs: Exploring Multimodal AI
- Week 3 at AI_devs: Mastering Data Organization and Retrieval
- Week 4 at AI_devs: Building AI Agent Tools and Interfaces
- Week 5 at AI_devs: Building Advanced AI Agents and course summary
Introduction
AI_devs (https://aidevs.pl) is a 5-week intensive course that teaches developers how to build AI-powered applications. Current edition of this course is particularly focused on AI Agent architecture - a way to create semi-autonomous systems that can understand, plan, and execute tasks using LLMs.
As Andrej Karpathy, a leading AI expert and founding member of OpenAI, noted:
Looking at LLMs as chatbots is the same as looking at early computers as calculators. We’re seeing the emergence of a whole new computing paradigm, and it is very early.
During this course, we’re learning exactly what this means in practice and how it connects to programming.
The course structure consists of daily lessons with some practical tasks. I’ve decided to publish weekly summaries of my progress, sharing what I’ve learned along the way. The source code for all my tasks will be published on github in the upcoming weeks.
During this first week, we covered several fundamental aspects of working with LLMs:
- Understanding how to interact with LLM APIs effectively
- Working with external data sources and context management
- Learning about LLM limitations and how to work around them
- Implementing optimization techniques for better performance
- Setting up production environments for AI applications
While these summaries will be brief compared to the extensive course materials, I hope they provide valuable insights into the world of practical AI development.
Day 1: Introduction to AI Agent Architecture
The first day focused on a fundamental concept: AI Agents are much more than just chatbots. We learned that building an effective AI Agent requires understanding four key stages of LLM interaction:
Understanding Phase
- Loading memory and external resources
- Expanding beyond base knowledge
- Initial analysis and processing
Action Planning
- Analyzing available tools and capabilities
- Creating structured sequence of actions
- Selecting appropriate methods and skills
Action Execution
- Implementing the planned actions
- Monitoring results and progress
- Handling errors and adjustments
Response Generation
- Synthesizing collected information
- Formatting results
- Delivering final output
An interesting insight from this lesson is that building AI Agents is still primarily a software engineering challenge - about 80% traditional programming and 20% LLM/prompt engineering. After completing this week’s practical tasks, I can definitely confirm this ratio.
Practical Task: Outsmarting an Anti-Captcha
In this task we had to bypass an “anti-captcha” system. Unlike traditional CAPTCHAs that verify you’re human, this one was designed to verify if you’re a bot! The system presented rapidly changing questions that required quick, accurate responses - quite hard, or even impossible to solve manually.
I built a solution in GoLang that:
- Fetched the anti-captcha question from the target website
- Passed the question to
GPT-3.5-turbofor interpretation (via OpenAI API) - Submitted the LLM’s response along with login credentials
- Retrieved a CTF-style flag from the successful login response
While the task might seem straightforward, it demonstrated the core concepts of programmatic LLM interaction:
- Prompt engineering for reliable responses
- Managing API communication with OpenAI
- Integrating LLM capabilities into a traditional web automation workflow
The main challenges were writing a good prompt and implementing the OpenAI API communication correctly.
Day 2: Working with Custom Data and Context
Day 2 covered integrating external data with LLMs. We focused on data formats, memory systems, and data transformation strategies.
The most interesting part was learning about memory systems implementation. Instead of just feeding all data into the model, we can build dynamic memory structures where the application:
- Searches through available knowledge based on conversation context
- Updates and organizes information autonomously
- Uses
vector databasesfor efficient information retrieval - Maintains relationships between different pieces of information
Key points about working with data:
- Use open formats: Markdown, TXT, JSON, YAML
- Avoid binary formats (PDF, DOCX)
- LLMs can’t read binary files (except Claude, which recently added PDF support)
- Converting binary files often loses formatting
- Lost formatting can lead to incorrect content interpretation
- Even simple things like images or links can confuse the model
- Transform data efficiently:
- Convert between formats (PDF → HTML → Markdown)
- Clean up unnecessary content
- Choose formats wisely - for example,
YAML can use about 30% less tokens than JSONfor the same data (tested with Tiktokenizer)
Practical Task: Structured Communication with LLM API
The task was focused on proper LLM communication patterns. Instead of writing code, we worked with an API that required specific message formats and prompts to extract data. I used Bruno for sending requests to provided API.
Are you interested in staying up-to-date with the latest developments in #Azure, #CloudComputing, #PlatformEngineering, #DevOps, #AI?
Follow me on LinkedIn for regular updates and insights on these topics. I bring a unique perspective and in-depth knowledge to the table. Don't miss out on the valuable content I share – give me a follow today!
Day 3: Understanding LLM Limitations
3rd day focused on the practical and theoretical limitations of Large Language Models. Understanding these limitations is crucial for building reliable AI applications.
The Transformer model, which powers modern LLMs, was originally designed for language translation. This explains why it excels at content transformation. Its key component - the attention mechanism - helps the model maintain focus on important parts while preserving context and relationships.
Core characteristics of LLMs:
- Better at transforming existing content than generating new
- Better at verifying content than transforming it
- Learn through content, not through real-world experience
- Have impressive but imperfect attention and context handling
When building LLM applications, we need to handle several practical limitations. First, there’s the matter of usage and costs. You need to carefully monitor token usage, keeping in mind that output tokens cost more than input ones. Implementing budget controls and monitoring systems for team usage is essential, as costs can quickly escalate without proper optimization strategies.
API limitations are another critical concern. Every LLM provider implements rate limits, restricting both requests per minute and tokens per day. You need to work within service quotas, consider your account tier limitations, and plan your scaling strategy accordingly. Proper error handling becomes crucial when dealing with these limits.
Performance is the third major consideration. Not every task requires the latest GPT-4 model - sometimes a simpler, faster model works better. You can optimize performance through parallel processing, caching mechanisms, and background processing for non-urgent tasks. The key is finding the right balance between speed and capability in your model selection.
Key takeaways:
- Monitor everything: tokens, costs, errors
- Use proper tokenizer settings for your model
- Consider platform limitations in your architecture
- Implement content moderation (both input and output)
- Not every task needs an LLM, sometimes traditional programming is a better solution
Practical Task: Smart JSON Repair
The task required fixing errors in a JSON file. The interesting part was deciding which fixes should be handled programmatically and which required LLM assistance.
I built a GoLang application that:
- Fixed simple math errors using code
- Used OpenAI API to verify and correct answers to open questions
- Combined both approaches for optimal solution
Sample source data:
{
"test-data": [
{
"question": "51 + 13",
"answer": 54
},
{
"question": "26 + 19",
"answer": 45,
"test": {
"q": "What is the capital city of Germany?",
"a": "???"
}
}
]
}
This task demonstrated a key principle: use LLMs only where they add value, not as a solution for everything.
Day 4: Optimization Techniques
Day 4 covered three main topics: prompt optimization, vector databases, and system performance improvements.
Vector databases are essentially search engines, similar to ElasticSearch or Algolia, but they search for semantic similarity instead of exact matches. They work with embeddings - numerical representations of text meaning. For example, when searching “Play Music”, the system converts this query into embeddings and might find related content about Spotify based on semantic similarity, not just matching words.
We also learned about some prompt optimization techniques:
- Using
meta-prompts: LLMs can help optimize other prompts Prompt compression: reducing token usage while maintaining effectivenessDebugging with LangFuse: analyzing and improving prompt performance
Key points:
- Vector databases store embeddings, not raw text
- The search process works in three steps:
- When saving: convert text to numbers using an embedding model
- When searching: convert search query to numbers the same way
- Find matches by comparing these numbers
- In our examples we used OpenAI’s
text-embedding-3-largemodel - Different models might work better for different languages
Practical Task: Robot Navigation Challenge
The task was to write a prompt that would generate robot navigation instructions. The robot understood four commands: UP, RIGHT, DOWN, LEFT, and needed to navigate a map with walls to reach a marked location.
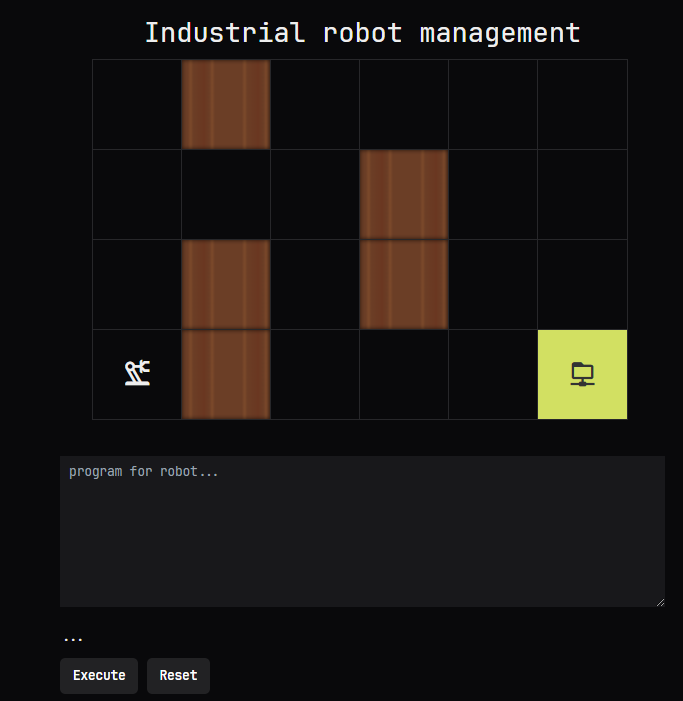
The response from LLM had to be in specific format:
<RESULT>
{
"steps": "UP, RIGHT, DOWN, LEFT"
}
</RESULT>
The challenge:
- The prompt couldn’t include ready-made steps
- We had strict token limits
- We used
GPT-4o-minimodel
I spent about an hour crafting and testing the prompt in OpenAI playground before submitting the final solution. While it seemed simple initially, getting the prompt just right with the token limitations proved quite challenging.
Day 5: Production Environment Setup
Day 5 covered deploying AI applications to production environments. While there was extensive content about server setup and configuration, in this post I’ll focus only on AI-specific aspects of deployment.
Most AI application deployment follows standard programming practices, but building LLM-based systems requires handling some unique aspects like:
Prompt Management and Version Control: tracking changes and versions of promptsVector Database Integration: proper setup and maintenance of vector databasesAPI Connections: managing sandbox modes and separate accounts for different environments
Note: In this course we’re focusing on using LLMs through APIs (like OpenAI), so we won’t cover topics related to hosting and deploying your own models (like in Azure).
Practical Task: Data Anonymization Pipeline
The most exciting task of the week involved building a data anonymization app. The system needed to:
- Download source data from provided URL
- Anonymize it according to some specific rules
- Submit anonymized data for verification
I built a GoLang application that handled this flow, but with an interesting twist - I used a local LLM instead of OpenAI’s API! Specifically, I used llama3 model running through ollama application.
This was my first experiment with local models, and I was positively surprised by the results. Running on an RTX4070Ti, the performance and effectiveness were quite impressive. While it’s not at the level of ChatGPT or Claude 3.5 Sonnet, having all data processed locally opens up interesting possibilities. I’ll definitely explore local models more in the coming days.
Useful Tools
Working with LLMs requires some specific tools. Here are the ones that we learned this week:
LangFuse: Like Application Insights but for LLMs. It provides comprehensive monitoring of token usage, costs, and prompt performance. Especially useful for debugging prompts through its playground-like interface and tracking model behavior in production.
https://langfuse.comPromptFoo: A testing framework for prompts. It allows automated testing of prompts against multiple examples, helping ensure consistency and quality of LLM responses. Essential for maintaining reliable prompt performance.
https://www.promptfoo.devFireCrawl: A tool for web content extraction that provides clean, markdown-formatted content from websites. Particularly useful when building systems that need to feed web content into LLMs.
https://www.firecrawl.devTiktokenizer: A crucial tool for counting tokens before sending them to the model. Helps optimize costs and prevent errors by ensuring we stay within model’s context limits. In our examples, we used the
Microsoft Tokenizer librarythat provides accurate token counting for different models.
https://tiktokenizer.vercel.appOllama: A tool for running LLM models locally. Surprisingly efficient and easy to setup, especially when running on decent GPU hardware.
https://ollama.com
Important Concepts
In addition to tools, Week 1 introduced some key concepts usefull for LLM development:
- Few-Shot Learning
- Teaching models through examples
- Carefully selecting diverse, representative cases
- Finding the right balance between too few and too many examples
- Using examples to reinforce desired behavior
- Retrieval-Augmented Generation (RAG)
- Expanding model’s knowledge with external data
- Implementing efficient data retrieval systems
- Converting content into embeddings for semantic search
- Managing context window limitations
- Chain of Thought
- Breaking complex reasoning into steps
- Guiding model through logical progression
- Making decision process explicit
- Improving accuracy through structured thinking
- Tree of Thoughts
- Exploring multiple reasoning paths simultaneously
- Evaluating different solution approaches
- Backtracking when needed
- Choosing the most promising path
- Thought Generation
- Giving model “time to think”
- Implementing explicit reasoning steps
- Using structured formats for thoughts
- Improving response quality through deliberation
Wrapping Up
It’s been an intense week of learning how to build AI applications. From understanding LLM limitations to implementing vector databases, from optimizing prompts to setting up monitoring - each day brought new insights into practical AI development.
Have you worked with any of these tools or concepts? Is there a particular topic you’d like me to explore in more detail? Let me know in the comments - I might prepare a dedicated post about it.
Next week, we’ll dive deeper into AI Agents development. Stay tuned!
Do you like this post? Share it with your friends!
You can also subscribe to my RSS channel for future posts.